Phoenix 內 200 萬 Websocket 連線之道
Gary Rennie 於 2015 年 11 月 3 日發表
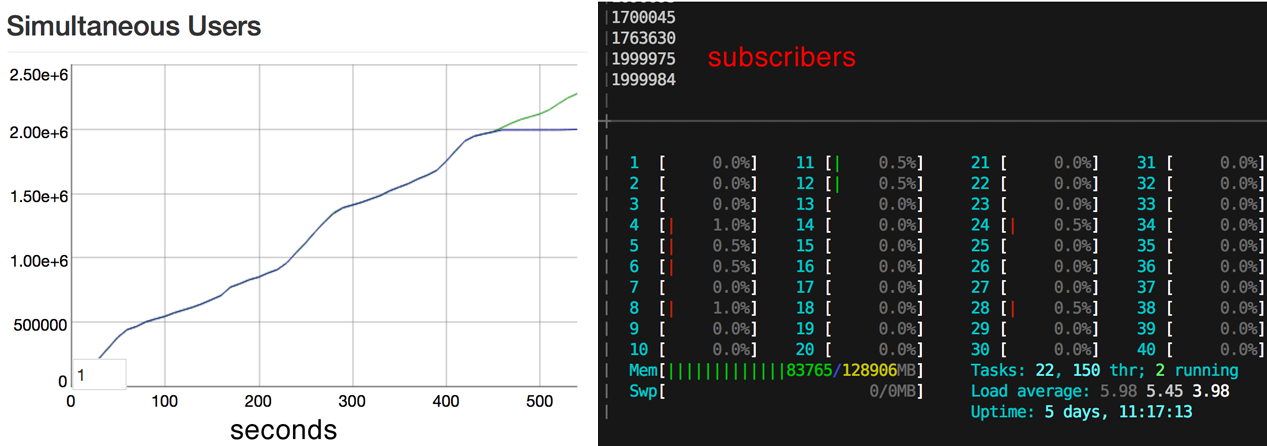
如果你最近關注 Twitter,你很可能會看到有關 Phoenix Web 架構能處理的同時連線數量的數字增加。這篇文章記錄了用於執行基準測試的一些技術。
起頭
幾個星期前,我在嘗試測定連線數,並成功在我的本機上建立 1 千個連線。我不相信這個數字,因此我在 IRC 上發文詢問是否有人測量過 Phoenix 頻道。結果證明沒有人做過,但核心團隊的一些成員發現我提供的 1 千個數字可疑地低。這就是旅程的開始。
執行基準測試的方法
伺服器
要基準測試可同時開啟的 Web Socket 數量,第一個需要的是一個 Phoenix 應用程式來接受 Socket。對於這些測試,我們使用了一個略微修改版的 chrismccord/phoenix_chat_application,位於 Gazler/phoenix_chat_example - 主要的差異是
- 發佈使用者已加入頻道的
after_join掛鉤已被移除。在測量同時連線時,我們希望限制所發送的訊息數。我們將針對這部分進行未來的基準測試。
大部分的這些測試都在 Rackspace 15 GB I/O v1 上執行 - 這些機器擁有 15 GB RAM 和 4 個核心。 Rackspace 友善地讓我們免費使用 3 部此類伺服器來執行基準測試。他們也讓我們使用 OnMetal I/O,它有 128 GB RAM 並在 htop 中顯示 40 個核心。
你可能想要做的另一個額外變更是在 conf/prod.exs 中移除 check_origin - 這表示應用程式可以連線,而無論使用的 IP 位址/主機名稱為何。
要啟動伺服器,只要 git clone 它並執行
-
MIX_ENV=prod mix deps.get -
MIX_ENV=prod mix deps.compile -
MIX_ENV=prod PORT=4000 mix phoenix.server
你可以透過拜訪 YOUR_IP_ADDRESS:4000 來驗證這是否正常運作
客戶端
要執行客戶端,我們使用了 Tsung。Tsung 是開源分散式負載測試工具,可以輕鬆壓力測試 Websocket(以及許多其他協定)。
當 Tsung 分配時運作的方式是使用主機名稱。在我們的範例中,第一台機器叫做「phoenix1」,它被指定到 /etc/hosts 中的 ip。其他機器「phoenix2」和「phoenix3」也應該在 /etc/hosts 中。
對於基準測試,在與 Phoenix 應用程式不同的機器上執行客戶端非常重要。如果兩者在同一部機器上執行,結果將無法真實呈現。
Tsung 是使用 XML 檔案進行設定。您可以在 文件 中閱讀有關特定數值的說明。以下是我們使用的設定檔(然而,數字已經降低以反映這裡的客戶端數量,對於較大的測試,我們使用了 43 個客戶端)。它每秒開始 1k 連線,最高可達 100k 連線。對於每個連線,它開啟一個 websocket,加入「rooms:lobby」主題,然後休眠 30000 秒。
我們使用了較長的休眠時間,因為我們希望保持連線開啟,以便在所有客戶端都連線後查看應用程式的回應性。我們會手動停止測試,而不是在設定檔中關閉 websocket(您可以使用 type="disconnect" 來完成此操作)。
<?xml version="1.0"?>
<!DOCTYPE tsung SYSTEM "/user/share/tsung/tsung-1.0.dtd">
<tsung loglevel="debug" version="1.0">
<clients>
<client host="phoenix1" cpu="4" use_controller_vm="false" maxusers="64000" />
<client host="phoenix2" cpu="4" use_controller_vm="false" maxusers="64000" />
<client host="phoenix3" cpu="4" use_controller_vm="false" maxusers="64000" />
</clients>
<servers>
<server host="server_ip_address" port="4000" type="tcp" />
</servers>
<load>
<arrivalphase phase="1" duration="100" unit="second">
<users maxnumber="100000" arrivalrate="1000" unit="second" />
</arrivalphase>
</load>
<options>
<option name="ports_range" min="1025" max="65535"/>
</options>
<sessions>
<session name="websocket" probability="100" type="ts_websocket">
<request>
<websocket type="connect" path="/socket/websocket"></websocket>
</request>
<request subst="true">
<websocket type="message">{"topic":"rooms:lobby", "event":"phx_join", "payload": {"user":"%%ts_user_server:get_unique_id%%"}, "ref":"1"}</websocket>
</request>
<for var="i" from="1" to="1000" incr="1">
<thinktime value="30"/>
</for>
</session>
</sessions>
</tsung>前 1k 連線
Tsung 在埠 8091 提供一個網路介面,可用于監控測試狀態。對於這些測試,我們唯一真正感興趣的圖表是同時使用者數。因此,我第一次在自己的機器上執行 Tsung 是在自己的機器上,同時在本地執行 Tsung 和 Phoenix 聊天應用程式。在這樣做時,Tsung 經常會崩潰 - 當發生這種情況時,您無法看到網路介面 - 這表示沒有可以顯示的圖表,但這是令人失望的 1k 連線。
再次嘗試前 1k 連線!
我在遠端架設了一台機器並再次嘗試基準測試。這次我得到了 1k 連線,但至少 Tsung 沒有崩潰。原因是系統範圍的資源限制達到了上限。為了驗證這一點,我執行了 ulimit -n,結果回傳 1024,這解釋了我為什麼只能得到 1k 連線。
從這一點開始,使用了以下設定檔。這個設定檔讓我們一路使用到了 200 萬連線。
sysctl -w fs.file-max=12000500
sysctl -w fs.nr_open=20000500
ulimit -n 20000000
sysctl -w net.ipv4.tcp_mem='10000000 10000000 10000000'
sysctl -w net.ipv4.tcp_rmem='1024 4096 16384'
sysctl -w net.ipv4.tcp_wmem='1024 4096 16384'
sysctl -w net.core.rmem_max=16384
sysctl -w net.core.wmem_max=16384第一個真正的基準測試
當我正在 IRC 中討論 Tsung 時,Phoenix 的建立者 Chris McCord 聯繫我,讓我知道 RackSpace 已為我們設定了一些執行個體,以供我們用於基准測試。我們開始使用以下設定檔來設定 3 個伺服器:https://gist.github.com/Gazler/c539b7ef443a6ea5a182
在我們啟動並執行後,我們將一台機器指定給 Phoenix,兩台用於執行 Tsung。我們的第一次真實基準測試最後約有 27k 連線。
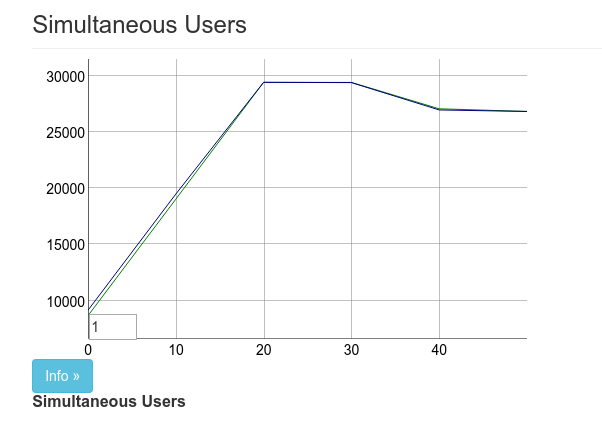
上述圖片中的圖表中有兩條線,上方的線標記為「使用者」,下方的線標記為「已連線」。使用者數會根據到達率提升。在多數的這類測試中,我們會使用每秒 1,000 名使用者的到達率。
結果出來後,José Valim 便透過 此 commit 立即著手解決
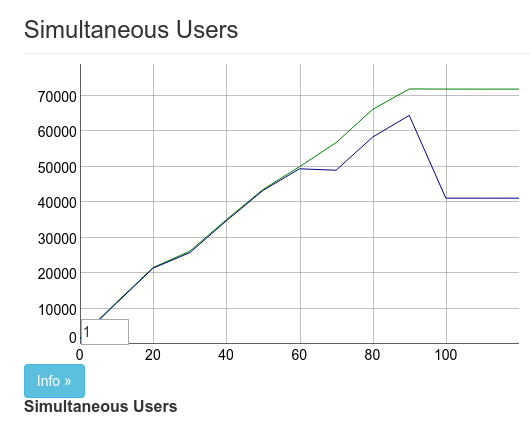
這是我們第一次的改善,也是一大躍進。所以我們獲得約 5 萬筆連線。
觀察變更
在我們第一次改善後,我們發現我們是在盲人摸象。如果我們有什麼方法能觀察正在發生的事情,那就太好了。幸運的是,Erlang 內建 observer,而且可以遠端使用。我們使用了 https://gist.github.com/pnc/9e957e17d4f9c6c81294 的下列技術開啟遠端觀察。
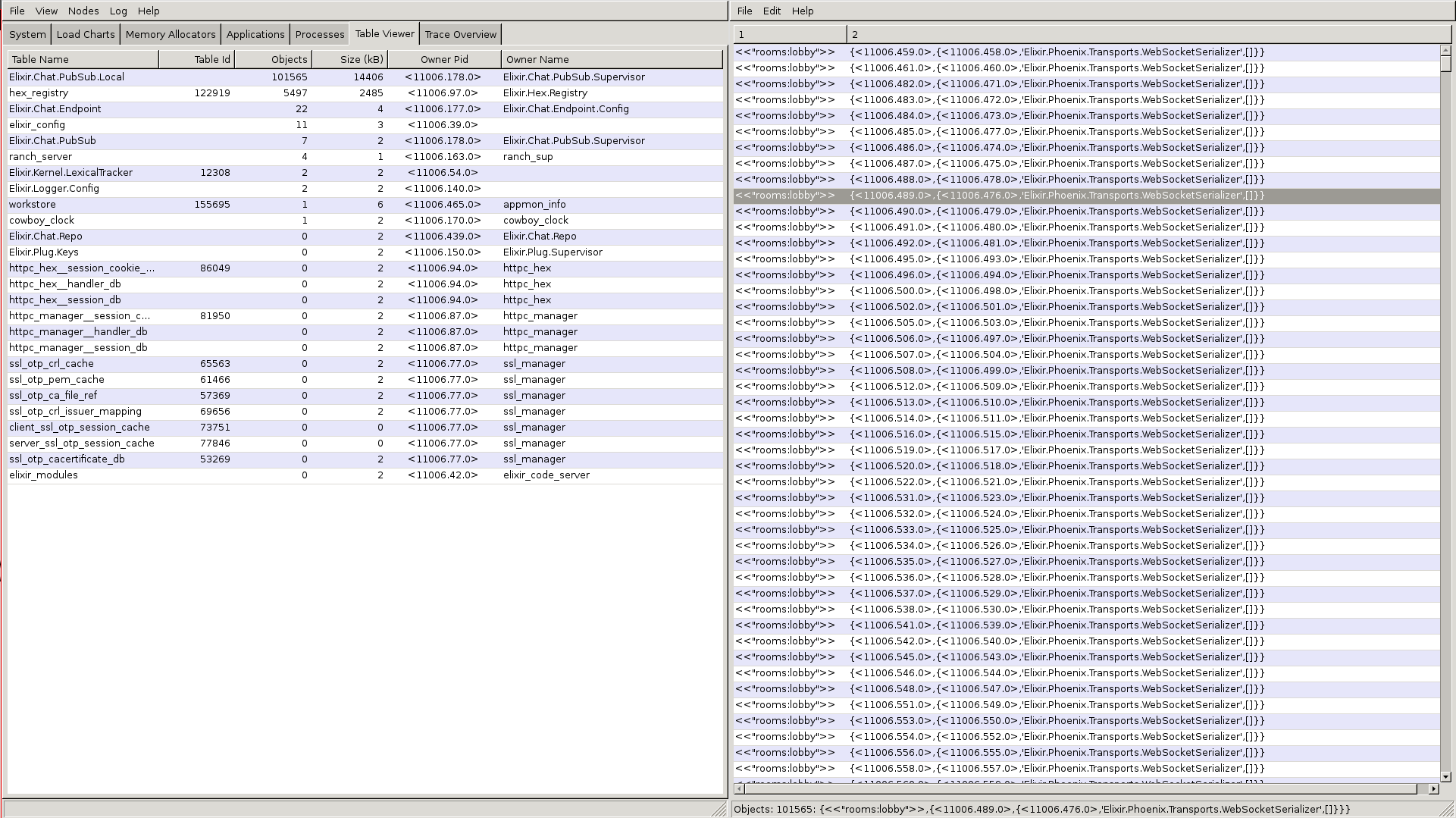
Chris 能夠使用觀察功能按照電子信箱大小排序程序。:timer 程序在電子郵件信箱中有約 4 萬則郵件。這是因為 Phoenix 每 30 秒執行一次心跳,確保客戶端仍連線中。
幸運的是,Cowboy 已處理此問題,所以在這個 commit 之後,結果看起來像
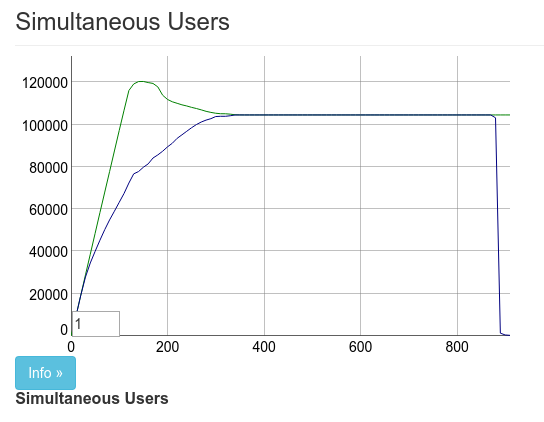
我實際上使用觀察中斷了 pubsub 的監督,這解釋了最後方 10 萬的下降。這是第二次效能提升 2 倍。結果是使用 2 部 Tsung 機器連線 10 萬筆同時連線。
我們需要更多機台
上方的圖片中有兩個問題。一是我們未達到完整數量(約 1.5 萬筆逾時),二是我們只能透過每位 Tsung 客戶(技術上來說是每組 IP 位址)產生 4 萬到 6 萬筆連線。對 Chris 和我來說,這還不夠好。除非我們能夠產生更多負載,否則我們無法真正看到限制在哪。
此時 RackSpace 已提供我們 128GB 的伺服器,所以我們實際上還有另一部可以使用。使用這類強大的機器作為被限制在 6 萬筆連線的 Tsung 客戶似乎是一種浪費,但這比機器閒置要好!Chris 和我各自建立了另外 5 部機器,這是另外 30 萬個可能的連線。
我們再次執行基準測試,並獲得了約 33 萬筆連線的客戶端。
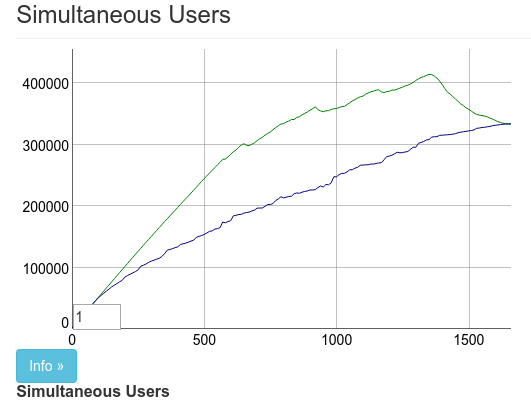
主要的問題是約 7 萬筆未真正連線到機器。我們無法找出原因。可能是硬體問題。我們決定嘗試在 128GB 機器上執行 Phoenix。必定不會有到達連線限制的問題,對吧?
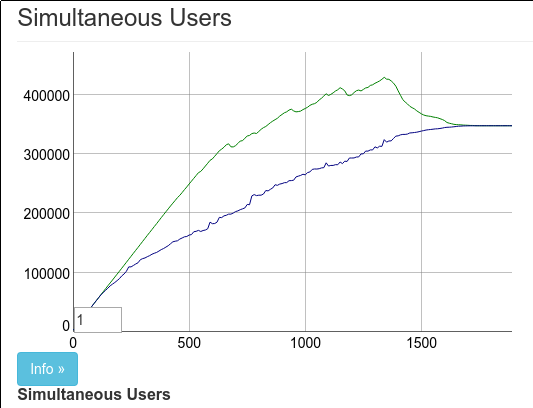
錯了。此處的結果幾乎與以上相同。Chris 和我認為 33 萬筆已經很不錯了。Chris 推文公布了結果,我們便結束了一天的工作。
放棄嘗試讓頻道達到極限——在有 333k 個用戶端的情況下。需要 8 個伺服器並使用其最大連接埠數才能達成,同時還有 40% 的內存剩餘。我們已經沒有伺服器了!
— 克里斯·麥考德(@chris_mccord)2015 年 10 月 24 日
了解 ETS 類型
在實現 330k 並且有 2 個相當容易的性能提升後,我們不確定是否還會有任何相同程度的性能提升。我們錯了。當時我沒有意識到,但我的同事加比·祖尼加(@gabiz)在VoiceLayer那週末一直在研究這個問題。他的提交給我們迄今為止最大的性能提升。您可以在拉取請求中看到變化。我也會在這裡提供,以方便大家閱讀
- ^local = :ets.new(local, [:bag, :named_table, :public,
+ ^local = :ets.new(local, [:duplicate_bag, :named_table, :public,這 10 個額外的字元讓圖表看起來像這樣
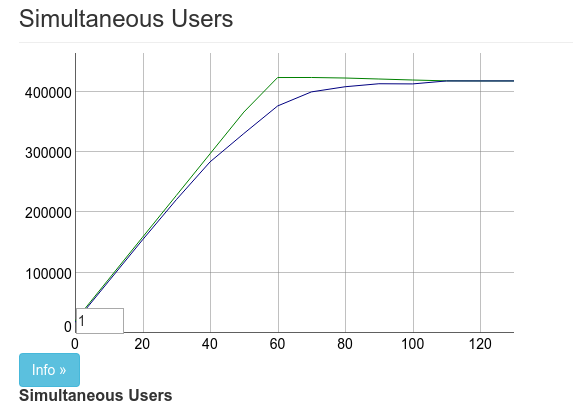
它不僅增加了同時連接的數量。它還允許我們將到達率也提高了 10 倍。這使得後續的測試更快了許多。
bag 和 duplicate_bag 的區別在於 duplicate_bag 允許同一個鍵有多個分錄。由於每個套接字只能連接一次並有一個 pid,使用 duplicate bag 對我們來說不會造成任何問題。
當連接數達到約 450k 時達到極限。這時 16GB 的機器已經用盡內存。我們現在準備好真正對更大的機器進行測試。
我太早放棄頻道評比,@gabiz 進行了一項優化,我們現在已經用盡我們的 4core/15gb 機器中的 450k 用戶端!
— 克里斯·麥考德(@chris_mccord)2015 年 10 月 25 日
我們需要更多機器
賈斯汀·施耐克(@mobileoverlord)在 IRC 中告訴我們,他和他的公司Live Help Now將在 RackSpace 上為我們設立一些額外的伺服器供我們使用。確切地說是有 45 台額外的伺服器。
我們設定了幾台機器並將 Tsung 的閾值設定為 1 百萬個連接。這是一個新的里程碑,而 128GB 機器輕易地達到了
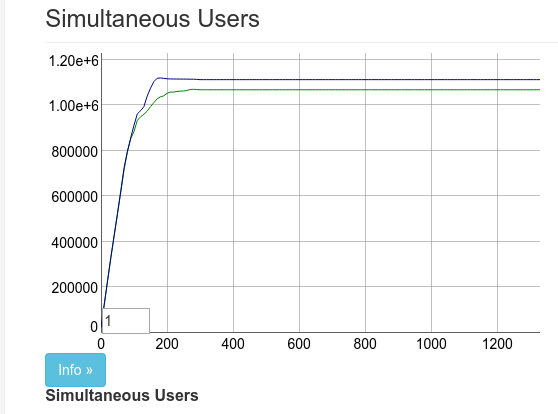
在一台更大型的@Rackspace機器上,我們剛剛在單個伺服器上獲得了 100 萬個 Phoenix 頻道用戶端!即時操作的快速螢幕截圖:https://#/ONQcVWWdy1
— 克里斯·麥考德(@chris_mccord)2015 年 10 月 26 日
就在賈斯汀完成設定所有 45 個機器的同時,我們確信 2 百萬個連接是有可能的。不幸的是,這並非如此。有一個新的瓶頸,而它只在有 130 萬個連接時才會出現!
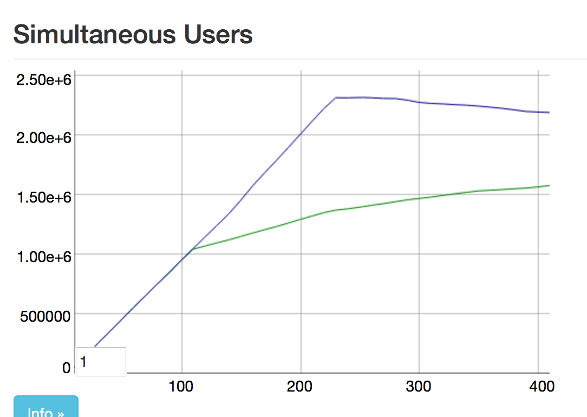
那便是如此,130 萬的連線數量已非常足夠,對吧?錯了。當我們新增至 130 萬的訂閱者時,我們開始在要求訂閱單一公開訂閱伺服器時,會定期發生逾時問題。我們並注意到廣播時間大幅增加,需要超過 5 秒的時間才能廣播至所有訂閱者。
Justin 對「(有用的)事物的」網路感到有興趣,並希望查看我們是否能針對 130 萬以上的訂閱者最佳化廣播,因為他在這一個訂閱等級中看到實際的使用範例。他想出將訂閱者分塊並將廣播作業平行處理,來對廣播進行分片處理構想。我們針對這個構想進行試驗,並將廣播時間縮減至 1 - 2 秒。但我們仍然有惱人的訂閱逾時問題。我們已達到單一公開訂閱伺服器及單一 ets 表格的極限。因此,Chris 開始著手彙總公開訂閱伺服器的工作,並發現我們可以將 Justin 的廣播分片處理與一組公開訂閱伺服器及 ets 表格結合使用。因此,我們依據訂閱者的 PID 對一組公開訂閱伺服器進行分片處理,而每個伺服器均管理自己對應的分片 ets 表格。這讓我們能到達 200 萬的訂閱者,且無逾時問題,並維持 1 秒的廣播時間。此項變更已存在於 此提交 中,並在併入至主程式碼之前進行微調。
在 40 核心/128 GB 盒子上執行 Phoenix 通道基準測試的最終結果。2 百萬用戶,受限於 ulimit#elixirlang pic.twitter.com/6wRUIfFyKZ
— 克里斯‧麥科德(@chris_mccord)2015 年 10 月 28 日
因此,這就是我們所擁有的:200 萬個連線!每當我們認為再也沒有什麼最佳化可做的時候,就會有其他想法冒出來,讓效能大幅提升。
2 百萬是個令人滿意的數字。但是,我們並未盡可能發揮機器效能,且我們在縮減每個 socket 處理器的記憶體使用方面尚未做出任何努力。此外,我們將執行更多基準測試。這組特定的基準測試僅針對同時開啟的 socket 數量設定。聊天室中有 200 萬用戶很棒,特別是在訊息得以如此迅速廣播時。然而,這並非典型的使用範例。以下列出一些未來的基準測試構想
- 一個頻道有 x 位用戶傳送 y 則訊息
- X 個頻道有 1000 位用戶傳送 y 則訊息
- 在多個節點上執行 Phoenix 應用程式
- 模擬傳送隨機數量的訊息,同時讓用戶隨機抵達及離開,模擬實際的聊天室
在這個基準測試中發現的改進將適用於 Phoenix 的後續版本。請密切注意關於未來基準測試的資訊,在這些測試中,Phoenix 將持續推動現代網路的極限。